Introduction
At dvlp.energy we are building the best GIS System to find and develop suitable sites for renewable energy projects. Our frontend application was initially developed using Alpine.js since its simplicity allowed us to rapidly adapt to customer feature requests and improve the product. In recent months, however, we rewrote our entire front end in React, so that we could take advantage of its greater capabilities to meet our customers’ needs. In this blog post, we’re going to share deeper reasons for why we made the investment to rewrite the frontend application, what tools we chose, and show off the improvements that resulted from this effort!
Reason for the Rewrite
Performance
As the product matured over the past few years, customers started using the application in more new (and computationally expensive!) ways than we imagined. While our initial technology choices were designed for rapid iteration of development, we recognized that we needed a fundamental change in order to continue growing with our customers. A major pain point with existing GIS systems is that they are slow, to the point of being frustrating to use, and this was an opportunity for us to find new technologies that would keep the application snappy.
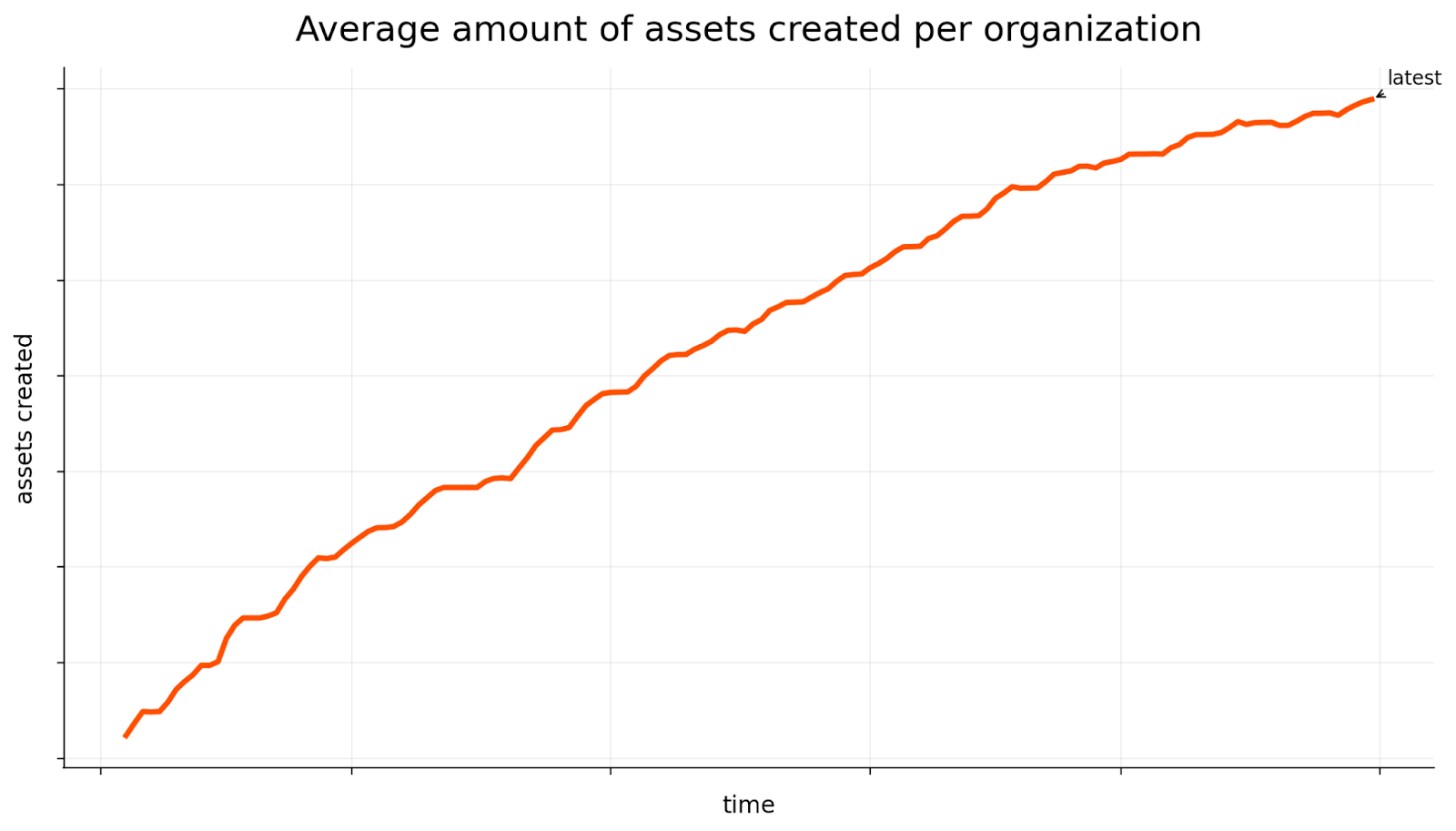
More Advanced Tooling
The framework we used, Alpine.js, is designed to be a small abstraction layer on top of vanilla JavaScript. It describes itself as: “Simple. Lightweight. Powerful as hell”. Alpine delivers on these three promises, but only in the appropriate use case. It’s excellent for adding interactivity to server-rendered pages or building smaller applications, but as our data volume grew and our UI became more complex, we found ourselves fighting against its minimalism rather than benefiting from it. Usage kept going up and as we tackled more performance issues, we found ourselves in a situation in which we could easily apply patches over problems, but we were unable to solve more fundamental issues present due to the framework. Tackling those issues would have required building a massive amount of inhouse tooling around Alpine, which we just did not have the time and resources to undertake. We wanted to focus on creating new features, but our developers’ efforts were being spent maintaining the existing functionality and performance.
The conventional wisdom is to avoid full rewrites and instead swap out components piece by piece. We considered this, but our Alpine codebase had grown without clear module boundaries. State was shared implicitly across components and dependencies ran in every direction. When everything is interdependent, replacing a single piece means untangling it. At that point, you’re doing most of the rewrite work anyways, just spread out and made harder to reason about! A clean break allowed us to design a sane architecture from the start.
What Technologies We Chose
We wanted a stack that gave us enough tools and flexibility to tackle performance issues with little maintenance overhead so that we could focus on shipping new high quality features. After some discussion, shared design docs, and a hackathon to get our hands dirty with different options, we settled on the following stack:
We picked React for a couple of reasons, the first and most important one being that it offers a lot of different hooks that allow deep performance optimization with minimal maintenance overhead. For example building something like useTransition from scratch in Alpine would be a horrible idea. Now we can simply call:
const [isPending, startTransition] = useTransition()
and get a performance optimization that previously would have been a nightmare to maintain.
Tanstack Query was chosen for a similar reason. We get minimal global state management and a caching engine out of the box without having to maintain it. This allows a lot of performance optimization with minimal maintenance cost.
Shadcn/ui would allow us to worry more about the important part of what a feature does and less about the details of how a design primitive should look like. It makes sure we can prototype and iterate at a much higher velocity while maintaining a beautiful design.
Bun is a fast JavaScript runtime, with out of the box support for JSX and Typescript. It aims for feature compatibility with Node.js and, while it but hasn’t reached that goal quite yet, most of the issues are related to running server side applications so the, and the speed improvements while using it makes the tradeoff well worth it. Hopefully Bun will continue to improve on the back of their recent acquisition by Anthropic.
Results of the Rewrite
The new performance that we achieved exceeded our expectations. As shown in the video, the difference is day and night. There were two main architectural strategies that paid off; optimistic updates and enhanced cache construction.
We now use optimistic updates for almost every client server interaction. This means that even before the server responds with the updated data, we can construct the cache locally to provide instant feedback for users. For example, when a user deletes a project from a list, instead of sending a request to the server and waiting for the response, we can now assume that this request will succeed, and immediately remove it from the locally referenced copy. The user can now continue using the application, and once the server responds, we update the cache with the server state. If any errors occur, we rollback to the previous cache state as this matches the previous successful response from the server - i.e. our source of truth. This simple feature means that for almost every interaction the user won’t notice any loading delays. Tanstack query does the heavy lifting for us, since it provides clean and safe abstraction that we can easily use instead of building our own solutions.
Tanstack query also gives us a good way to interact with the cache. This way, even if a user does not have the full data in cache required to load a component, we can now construct a preview component by leveraging the existing cache to instantly show a result to the user, while we are fetching the complete data in the background.
Outcome
In conclusion, we managed to solve the most critical issues facing our users, while increasing developer satisfaction and future-proofing our technology stack. We achieved this from taking on an ambitious rewrite in a thoughtful and considerate manner, involving both individual research and team collaboration/experimentation. This is the approach to building software we love at Dvlp, so if this sounds interesting to you, check out our careers page to check for any open positions. If you would like to get in touch with us to discuss anything else from this post, feel free to reach out via email at contact@dvlp.energy.
Johan Trieloff & Conor Flynn
Engineering at DVLP